
Data Analytics
Digital Intelligence is the foundation of everything we do, and the inspiration for our ideas and research.
Get a QuoteBig Data often helps the organisational or business decisions. The concept of Big Data and Analytics is the complex process of scrutinizing the huge data sets with varied permutations and combinations to discover the data structure, and data relations. Big Data Analytics helps the organisation to interpret the customer pulse, customer feedback and contributes towards the business decisions. Organisation using Big Data Analytics, are dealing with terabytes of data that is received from different means like and processes to derive a logical equation that contributes to the strategic planning. Big Data overrules the capacity of traditional RDBMS available in the market. As the term says, it is the capacity of Big Data is very huge to manage or process.
Why Data Analytics is Important?
Volume, Velocity and the variety are main features of Big Data. Fast moving trends of internet operations, usage, Artificial Intelligence, Social Media, and Mobile World are contributing to the intricacy of Data. Various sources that contribute towards Big Data are Chats, Facebook, What’s App, Files, feedback posted on sites, customer reviews, feedback, and images posted on Social Media.
Generally the data in the form of chats, SM conversations, Facebook chats/images and customer feedbacks, views and reviews content is the available data that is in unstructured format. Leverage this unstructured data by applying AI and converting it into meaningful structured data that helps the Organisations to derive best business equations is the capacity of Big Data Analytics.

Benefits of Data Analytics
-
Sentiment Analysis
-
Customer Churn Analysis
-
Advertisement Analysis
-
Predictive Analysis
-
Weather Forecasting
-
Health Care Analysis
Data Analysis Frameworks
Big Data Architecture & Patterns
The Best Way to a solution is to “Split the Problem”. This Architecture helps in designing the Data Pipeline with the various requirements of either the Batch Processing System or Stream Processing System. Secured data flow can be viewed under Big Data Architecture in 6 layers that ensures data security.
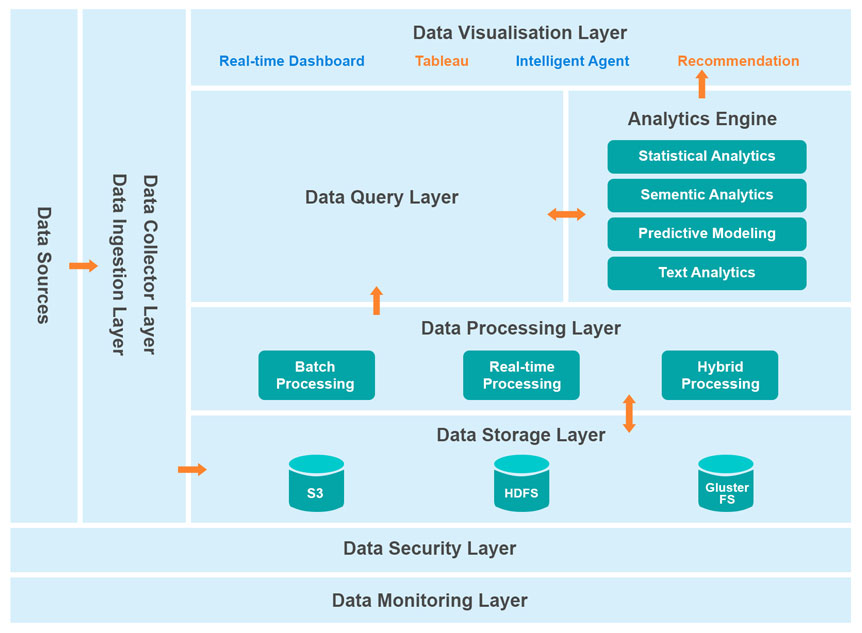






Silver Touch Data Analytics Services
Data Analytics Consulting
- Silver Touch assists our customers in defining their big data strategy and selecting appropriate technology tools and processes to achieve the strategic objectives.
- We offer vendor-neutral recommendations that are tailored to customer specific requirements, current technology landscape, preferences, objectives and budget.
Application Development, Infrastructure Set-Up and Systems Integration
- Silver Touch creates and delivers optimum and engaging features to drive user engagement on a single and secure platform. Make scaling easier by processing high-velocity and high-volume transactions and events more efficiently and in a faster time frame.
Maintenance & Support
- We have well versed off-shore team for handling the entire lifecycle of Big Data implementation- Installation, Integration, Configuration and Monitoring of Hadoop Clusters with optimum performance. We provide Big Data solution maintenance and support services addressing all the functional components including Data Provisioning, Data Management and Data Consumption.
- Big Data Analytics allows the business owners, experts and others involved in decision making to churn the unstructured data which was meaning less and a scrap, and by applying the technology landscapes, derive meaningful equations for business decisions.
Data Analytics Solutions
Data & Analytics Strategy
- Quantifiable business outcomes with an
- Agile and Data-Driven approach
Data Augmentation
- Augment Digital Assets with AI-enabled analytics tools
- 360-degree customer views
Data Management
- Synthesize and Analyze Data from Ecosystem
- Empower Business Decisions
Big Data Visualization
- Interactive Dashboards
- Real-Time Illustrative Graphs
Do you want to connect with us?
![]()
Confidential & Secured
- This form is Secured with Validations.
- Your Privacy is our utmost priority.
- We will not reveal any of your info.
- It will be used to contact you for Project purpose only.